
Разработки СО РАН - каталоги программ и БД
Поиск по каталогам:
|
2015-05-19
Назначение Программа предназначена для поиска односвязных областей на изображении. Область применения Задача выделения односвязных областей на изображении является актуальной при решении многих прикладных задач: обработка спутниковых фотографий поверхности земли, обработка снимков биологических объектов под микроскопом, обработка медицинских данных, локализация текста на изображениях. Полученные односвязные области на изображении могут быть использованы для дальнейшего анализа изображения (например, для распознавания образов). Используемый алгоритм Набор пикселей исходного изображения преобразуется в множество точек векторного пространства RGBXY (три цветовые координаты и две пространственные). Цветовые координаты каждой точки нормализуются. Для решения задачи выделения односвязных областей на изображении применяется алгоритм кластеризации. Множество точек пятимерного пространства разбивается методом кластеризации на подмножества точек, близких друг другу. Для вычисления расстояния между точками используется Евклидова метрика. Для изображения ищется самый популярный интервал цветов. На изображении находится точка, попадающая в самый популярный интервал цветов, и имеющая одну соседнюю точку такого же цвета. Данная точка выбирается в качестве начальной для алгоритма кластеризации. По всем точкам строится минимальное остовное дерево. Для начальной точки и всех точек, не присоединённых к дереву, вычисляется расстояние между точками. Точка с наименьшим расстоянием до начальной точки присоединяется к дереву ребром с весом, равным данному расстоянию. Далее для всех точек (вершин) в дереве вычисляются расстояния для всех «неиспользованных» точек, а точка с наименьшим расстоянием присоединяется к дереву. Алгоритм продолжается пока все точки не будут присоединены к дереву. Для выделения односвязных областей требуется разбить данное дерево на поддеревья. Для этого начнём удалять рёбра с весом больше некоторого порога t . После этого дерево разбивается на поддеревья, представляющие собой односвязные области на изображении. В алгоритме выполняется проверка, что размер полученных кластеров после разбиения превышает некоторый порог minimum_cluster_size; если размер кластера меньше данного порога, ребро, удаление которого привело к такому разбиению, не удаляется. Таким образом, на каждой новой итерации алгоритм производит более глубокую кластеризацию. Подробное описание алгоритма - в статье [1]. [1] Белим С.В., Кутлунин П.Е. Использование алгоритма кластеризации для разбиения изображения на односвязные области // Наука и образование: электронное научно-техническое издание, 2015, №.3, URL: http://technomag.bmstu.ru/doc/759275.html]. Функциональные возможности Изображение размером 256х256 пикселей на компьютере с двухъядерным процессором Intel Core i5 2.26GHz обрабатывается около 3 минут. Минимальное остовное дерево для этого изображения занимает в памяти 12 Мб. Ограничений со стороны алгоритма на размер обрабатываемого изображения не накладывается. В качестве входных данных подаётся изображение для обработки. Результатом работы программы является набор изображений с односвязными областями на белом фоне (одна область на одном изображении). На вход подаётся 5 обязательных параметров: 1) file_name - путь к изображению, которое необходимо разбить на односвязные области; 2) r_coefficient - коээфициент уменьшения расстояния между рёбрами. Рёбра, превышающие значение r_coefficient * MAX_DISTANCE на очередной итерации, удаляются из дерева, тем самым распадаясь на поддеревья, представляющие собой односвязные области на исходном изображении. MAX_DISTANCE - максимальное расстояние между двумя рёбрами в исходном остовном дереве; 3) percent - процент от MAX_DISTANCE, при достижении значения которого алгоритм останавливает свою работу; 4) minimum_cluster_size - ограничение на минимальное количество пикселей в односвязной области; 5) color_intervals - количество цветовых интервалов, используемое для определения наиболее популярного для исходного изображения интервала и выбора первоначальной точки для построения дерева из этого цветового интервала. После запуска программы в директории расположения программы будет создана папка с таким же названием, как исходное изображение. Внутри папки будут созданы директории с номерами, обозначающими номер итерации (глубину кластеризации). Внутри соответствующих папок будут размещены изображения с односвязными областями. Инструментальные средства создания Программа написана на языке Java. Для написания использовались стандартные библиотеки классов JDK, в том числе классы из пакетов java.awt и javax.imageio для работы с изображениями. Вложение Прикреплён архив imagesegmentationexample.zip, в котором представлены результаты работы программы для изображения «Перцы» размером 100х100 пикселей. Программа запускалась со следующими параметрами: r_coefficient=0,8; percent=5; minimum_cluster_size=30; color_intervals=16. Внутри архива папка level7 содержит результаты кластеризация изображения на седьмом уровне кластеризации. |
||||||||||||
|
2015-05-13
Область применения - анализ данных, численные методы. Вейвлет-системы дают ряд преимуществ для широкого круга задач перед классическими ортогональными системами функций благодаря своим аппроксимационным свойствам и локализации во временной и частотной областях. Вейвлеты чрезвычайно перспективны для применения в задачах обработки сигналов, распознавания образов, сжатия информации. Программа позволяет построить прямое и обратное вейвлет-преобразование на базе полиномиальных сплайнов. В программе реализованы следующие возможности:
Алгоритм реализован для полиномиальных сплайнов степени m={2,3,4}. Объем входных-выходных данных для обратного вейвлет-преобразования:
Входным параметром для прямого вейвлет-преобразования является функция, выходными данными является набор коэффициентов преобразования (соответствует второму столбцу таблицы). В приложениях важно уметь решать две следующие задачи:
Решение первой задачи называется прямым вейвлет-преобразованием, решение второй задачи - обратным вейвлет-преобразованием. Поскольку носители построенных вейвлет-функций содержат конечное, не зависящее от дефекта, число частичных отрезков, то они очень хорошо локализованы во временной области. Т.к. они являются линейными комбинациями фиксированного числа B-сплайнов, то они хорошо локализованы и в частотной области. Поэтому коэффициенты разложения по ним непериодического сигнала несут как информацию о его поведении на коротком отрезке времени, так и о его "мгновенном спектре". Используемые материалы - работы заведующего кафедры Высшей математики Поволжского государстенного университета телекоммуникаций и информатики д.ф.-м.н. Блатова Игоря Анатольевича, в частности алгоритм вейвлет-преобразования на основе полиномиальных сплайнов, используемый в основе программы. Инструментальные средства создания - C++ Builder 6. Во вложении два главных файла:
Литература:
|
||||||||||||
|
2015-03-30
Гибридный локальный поиск для задачи маршрутизации транспортных средств с распределенными поставками
Область применения - логистика, транспортные задачи. Назначение - нахождение приближенных решений для задачи маршрутизации транспортных средств с разделеннымы поставками (Split Delivery Vehicle Routing Problem) Постановка задачи. В задаче маршрутизации транспортных средств неограниченный автопарк одинаковых транспортных средств расположен на складе. Каждое транспортное средство имеет фиксированную вместимость. Маршрут транспортного средства должен начинаться и заканчиваться на складе. Есть множество клиентов, рассположенных на плоскости. Каждый клиент имеет заданный запрос на доставку. Задача заключается в поиске набора маршрутов транспортных средств с минимальной суммарной длиной маршрутов при условии, что все клиенты будут обслужены. В задаче маршрутизации транспортных средств с разделенным обслуживанием (SDVRP) каждый клиент может быть посещен несколько раз, и поставки по его запросу могут быть разделены между транспортными средствами. Используемый алгоритм - гибридная метаэвристика, сочетающая в себе локальный спуск по чередующимся окрестностям и стохастический поиск с запретами. Подробно описан в прилагаемом файле. Функциональные возможности - программа позволяет находить приближенные решения с малой погрешностью для задачи маршрутизации транспортных средств с разделенными поставками. При размерности до 288 клиентов алгоритм находит решение с погрешностью не более 3%. Ограничение на размерность задачи отсутствует, но при большей размерности требуется больше временных ресурсов. Инструментальные средства создания - Java 6.0, Eclipse IDE. Исходный код находится в прикрепленном архиве. Для запуска работы необходимо установить Eclipse или любую другую IDE для работы с Java. Главный класс находится в пакете "tests". Один из них для запуска одного из примеров, другой для вычисления всего множества примеров. Также в приложении есть рисунок, в котором приведен результат работы программы для размерности в 64 клиента. Красным выделены клиенты с разделенной поставкой. Алгоритм опубликован в статье: Alexey Khmelev, Yury Kochetov. A Hybrid Local Search for the Split Delivery Vehicle Routing Problem. International Journal Of Artificial Intelligence 2015, Vol 13, 1 |
||||||||||||
|
2014-12-31
Назначение - программа предназначена для квантования и сокращения размерности векторного пространства спектральных признаков изображения. Область применения - для сокращения размерности данных в химии, биологии, медицине, в производственных процессах для исследования поверхности металлов и др., в сельском хозяйстве, лесоводстве при автоматизации классификации сельскохозяйственных культур, лесных угодий при картировании, инвентаризации, оценке площадей, прогнозирования урожая и других. Используемый алгоритм - Данные дистанционного зондирования Земли могут иметь большой объем и размерность (число спектральных каналов). Актуальной является задача предварительного сокращения этого объема, например, в задачах кластеризации или классификации. Обычно каждый спектральный канал представлен 8-битовым машинным словом, т.е. уровень серого тона может пробегать целочисленные значения от 0 до 256. Квантование означает, что размер ячейки квантования увеличивается с уменьшением числа уровней квантования, благодаря этому исходные вектора объединяются. При этом число уровней квантования по каждому каналу может быть разным. Чтобы определить их соотношение, строится ковариационная матрица спектральных векторов данных, затем определяются собственные значения матрицы. Для нахождения собственных чисел и векторов ковариационной матрицы векторов признаков используется метод Якоби [1]. При квантовании для меньшей потери информации ячейка квантования в собственном пространстве (ортонормированном) векторов должна оставаться гиперкубической. При этом условии разброс данных по каждому направлению, определяемый соответствующим собственным числом, должен быть пропорционален числу уровней квантования. Сохраняя число уровней серого по каждой оси собственного пространства целым числом от 0 до 255, мы получим максимально возможное число уровней равным 256 и минимальное для задач классификации 2. Учитывая вышесказанное, если отношение какого-либо собственного числа к максимальному меньше 1/128, то соответствующая ось собственного пространства может не рассматриваться. Для задачи кластеризации часто требуется максимальное число уровней квантования существенно меньшее 256, поэтому число отсеченных осей возрастет. Соответственно размерность пространства, связанная таким образом с детальностью рассмотрения, уменьшится [2]. Исходное изображение данной программой переписывается в новой системе координат собственного пространства в виде raw-файла. Описание применения для сокращения размерности и кластеризации [3] по картированию промышленных загрязнений [4] на сайте http://loi.sscc.ru/lab/WEBLAB/InfresLab2013/sidorova_pollution.htm. Рассматривалось изображение Омской области (около 57 Мбайт) в семи спектральных каналах со спутника ИСЗ “ Landsat-8” (разрешение 15 м, получен 08.02.2014). Предварительно было осуществлено сокращение размерности векторного пространства спектральных признаков с семи до трех. Этого оказалось достаточно для требуемой детальности кластеризации. Детальность, различная по полученным кластерам, определялась делимым иерархическим гистограммным алгоритмом [3] для предельной отделимости кластеров d=0.15 (0<d<1). 1. Н.Н. Калиткин. Численные методы. под ред. А.А. Самарского. Москва “Наука” 512 с 1978. 2. V.S. Sidorova. Contextual Clustering Multispectral Data of Remote Sensing the Earth. Труды Международной научной конференции. “Актуальные проблемы вычислительной и прикладной математики 2014” Июнь 8-11, 2014, Академгородок, Новосибирск, Россия. С. 108. 3. V.S. Sidorova. Detecting Clusters of Specified Separability for Multispectral Data on Various Hierarchical Levels. Pattern Recognition and Image Analysis, 2014, Vol. 24, No. 1, pp. 151–155. (SCOPUS) 4. Программа фундаментальных исследований по стратегическим направлениям развития науки Президиума РАН № 43. Функциональные возможности - Принципиальных ограничений на память программа не имеет. Только объем памяти используемого компьютера может ограничить размер обрабатываемого файла. Обработка изображения производится при построчном сканировании его. Инструментальные средства создания - Алгоритм реализован в программной среде системы объектно-ориентированного программирования Visual C++ версии 5.0 фирмы Microsoft c библиотекой классов MFC, разработанной для ОС Windows. |
||||||||||||
|
2014-12-31
Назначение: программа предназначена для вычисления и сохранения в виде raw-файла текстурных признаков CONTEXT для всех пикселей полутонового изображения. Область применения: Вычисляемые признаки системы CONTEXT могут быть использованы для математического описания статистических текстур изображения - в химии, биологии, медицине, в производственных процессах для исследования поверхности металлов и др., в сельском хозяйстве, лесоводстве для автоматизации классификации сельскохозяйственных культур, лесных угодий при картировании, инвентаризации, оценке площадей, прогнозирования урожая и других. Используемый алгоритм - Вычисляются статистические текстурные признаки CONTEXT, определяемые в пикселе как гистограмма уровней серого тона в его окрестности [1]. Использование признаков CONTEXT для неконтролируемой классификации изображений леса на аэроснимках с помощью алгоритма [2] описано и иллюстрировано на сайте http://loi.sscc.ru/lab/RFFI2013/RU/sidorova_separability_TEXTURA.htm. Использование контекстных характеристик требует предварительного сокращения размерности и квантования пространства спектральных признаков. Достоинство контекстной характеристики состоит в том, что в отличие от общепринятой одноканальной текстуры, может быть рассмотрена «цветная», многоспектральная. Кроме того, в качестве текстурных признаков непосредственно используются значения гистограммы в окрестности пикселя (а не формируются из нее сложные, долго вычисляемые формы). На сайте проиллюстрировано применение признаков для автоматизации распознавания леса на аэроснимках определенного масштаба. Наземная таксация (точное выборочное измерение параметров деревьв и характеристик лесных сообществ) осуществляется лесоводами в наиболее однородных частях контуров, построенных визуальным дешифрированием. Однако, визуальному дешифрированию свойствен субъективизм. Автоматизация в описании текстур и сегментации изображения позволяет избежать этого недостатка. Полученные карты кластеров по признакам CONTEXT оказались очень похожими на аналогичные карты по признакам модели SAR. Новая карта несколько больше соответствует карте наземной таксации: лиственные насаждения разделились по кластерам более точно, меньшим оказалось как общее число кластеров, так и число кластеров с узкими сегментами, находящимися на границах различных тексту в плоскости изображения. 1. Gong P and P Howarth Frequency base classification and grey level vector reduction for land use identification. // PE&RS, Vol.58, No.4, April 1992, PP.423-437 2. V. S. Sidorova. Detecting Clusters of Specified Separability for Multispectral Data on Various Hierarchical Levels. // Pattern Recognition and Image Analysis, 2014, Vol. 24, No. 1, pp. 151–155... Функциональные возможности - признаки могут не вычисляться заранее и храниться в отдельном файле, их расчет может быть встроен непосредственно в алгоритм кластеризации. Принципиальных ограничений на память программа не имеет. Только объем памяти используемого компьютера может ограничить размер обрабатываемого файла. Инструментальные средства создания - Алгоритм реализован в программной среде системы объектно-ориентированного программирования Visual C++ версии 5.0 фирмы Microsoft c библиотекой классов MFC, разработанной для ОС Windows. При разработке программы использовался механизм многодокументного интерфейса MDI. |
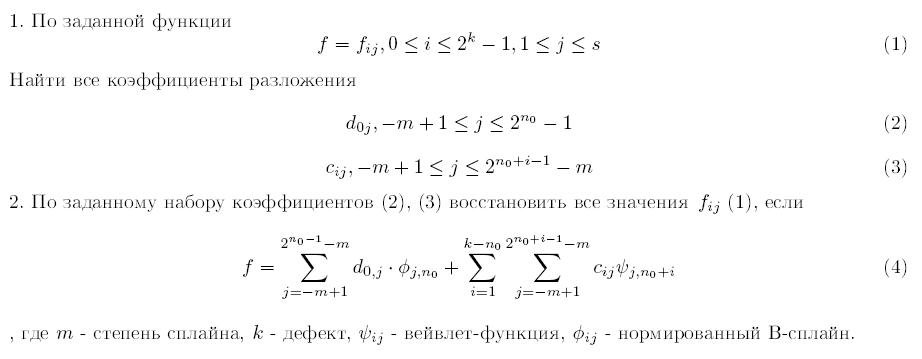
- « первая
- ‹ предыдущая
- …
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- …
- следующая ›
- последняя »